说明:这是我大三的一个分析商品关联度的项目。主要是用Python将出库记录转换为购物篮形式和Apriori关联分析。
关联分析
关联分析又称关联挖掘,就是在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。可从数据库中关联分析出形如“由于某些事件的发生而引起另外一些事件的发生”之类的规则。如“67%的顾客在购买啤酒的同时也会购买尿布”,因此通过合理的啤酒和尿布的货架摆放或捆绑销售可提高超市的服务质量和效益。又如“‘C语言’课程优秀的同学,在学习‘数据结构’时为优秀的可能性达88%”,那么就可以通过强化“C语言”的学习来提高“数据结构”教学效果。
关联分析中所需的两个度量公式:
- 频繁项集度量支持度(support):
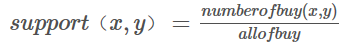
- 关联规则度量置信度(confidence):
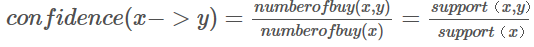
置信度的值应接近于1,且显著大于人们购买Y的支持度,即如果购买X,Y的顾客很少,那么该条还是没有价值的,支持度展示了关联规则的统计显著性,置信度展示关联规则的强度。
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。
分析过程
数据预处理
源表格进行处理,仅保留订单号和商品编号
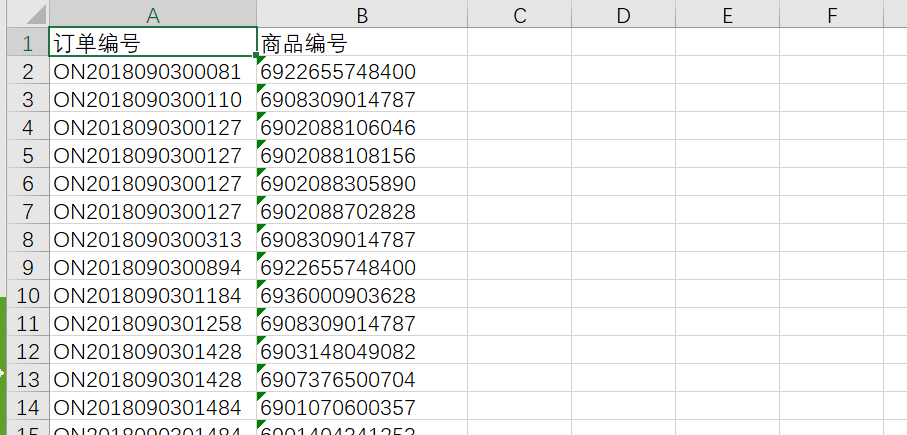
然后将其转换为购物篮形式,就像这样。
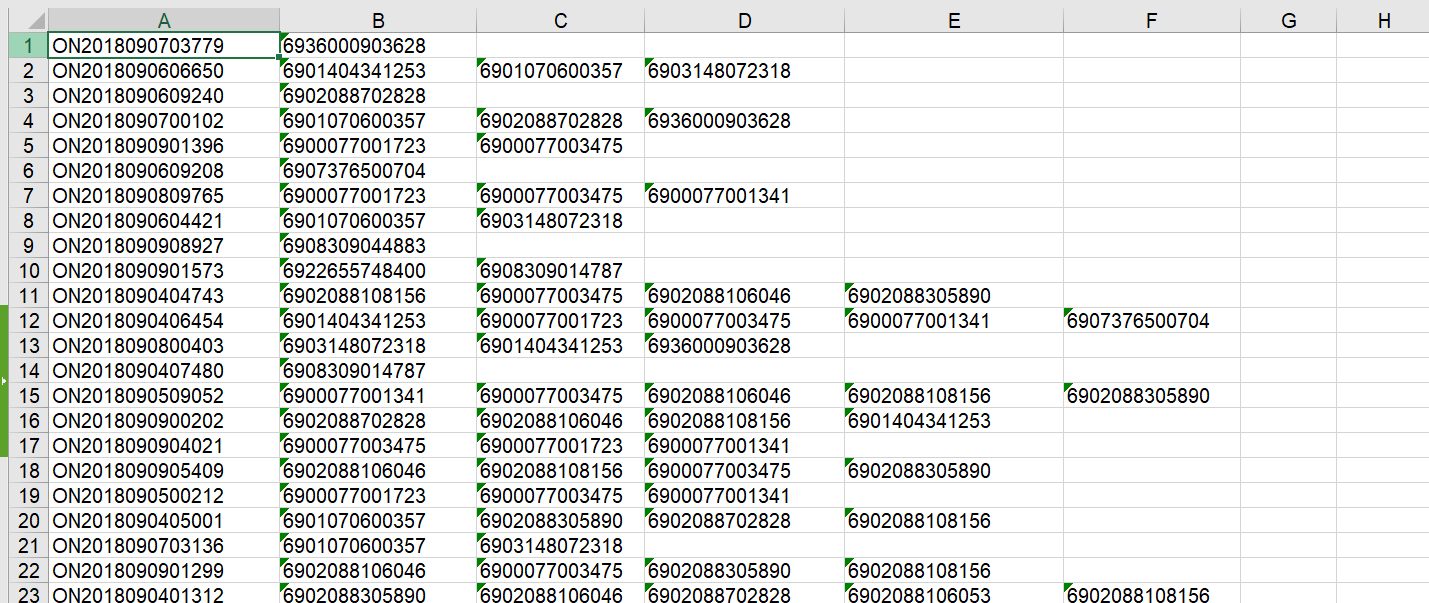
代码如下:
import xlrd,xlwt
class ExcelControl():
def __init__(self):
self.fliePath = "./gard.xlsx" #源excel路径
"""
读取excel文件
"""
def excelRead(self):
data = xlrd.open_workbook(self.fliePath)
sheet = data.sheets()[0]
rows = []
max_rows = sheet.nrows
for row in range(1,max_rows):
row_value = sheet.row_values(row)
rows.append(tuple(row_value))
rows = list(set(rows))
return rows
"""
删除出库单+商品名一样的东西,然后合并成一个字典
"""
def merge(self):
data = self.excelRead()
data_dict = {}
for d in data:
if d[0] in data_dict.keys():
data_dict[d[0]].append(d[1])
else:
data_dict[d[0]] = [d[1]]
return data_dict
"""
遍历字典 写入excel
"""
def excelWrite(self):
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = book.add_sheet("result",cell_overwrite_ok=True)
data_dict = self.merge()
count = 0
for k in data_dict.keys():
value = data_dict[k]
k_count = 0
sheet.write(count,k_count,k)
for v in value:
sheet.write(count,k_count+1,v)
print(count,k_count,v)
k_count += 1
count += 1
book.save("./result.xls")
if __name__ == '__main__':
excel = ExcelControl()
excel.excelWrite()关联分析过程
原先程序借鉴某篇文章,但是具体哪篇文章由于间隔太长已经遗忘,先把代码放上来。
主程序main.py
from __future__ import print_function
import pandas as pd
from sample import *
inputfile = './data_clean.xls' # 输入文件路径
outputfile = './output.xls' # 结果文件路径
data = pd.read_excel(inputfile, header=None)
print(u'\n转换原始数据至0-1矩阵...')
ct = lambda x: pd.Series(1, index=x[pd.notnull(x)]) # 转换0-1矩阵的过渡函数
b = map(ct, data.as_matrix()) # 用map方式执行
data = pd.DataFrame(list(b)).fillna(0) # 实现矩阵转换,空值用0填充
print(u'\n转换完毕。')
del b # 删除中间变量b,节省内存
support = 0.03 # 最小支持度
confidence = 0.4 # 最小置信度
ms = '-' # 连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符
find_rule(data, support, confidence, ms).to_excel(outputfile) # 保存结果
print("计算结束!")调用程序sample.py
from __future__ import print_function
import pandas as pd
def connect_string(x,ms):
x = list(map(lambda i:sorted(i.split(ms)),x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i,len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r
def find_rule(d,support,confidence,ms = u'--'):
result = pd.DataFrame(index=['support','confidence'])
support_series = 1.0*d.sum()/len(d)
column = list(support_series[support_series > support].index)
k = 0
while len(column) > 1:
k = k+1
print(u'\n正在进行第%s次搜索...' %k)
column = connect_string(column,ms)
print(u'数目:%s...'%len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only=True) # 新一批支持度的计算函数
# 创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf, column)), index=[ms.join(i) for i in column]).T
support_series_2 = 1.0 * d_2[[ms.join(i) for i in column]].sum() / len(d) # 计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) # 新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column: # 遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j] + i[j + 1:] + i[j:j + 1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) # 定义置信度序列
for i in column2: # 计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))] / support_series[ms.join(i[:len(i) - 1])]
for i in cofidence_series[cofidence_series > confidence].index: # 置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort_values(['confidence', 'support'], ascending=False) # 结果整理,输出
return result在做项目时,还使用了知乎@danger ace使用易语言编写的购物篮分析软件,对Python不太熟的同学可以考虑一下。文章及下载地址:易语言采用Apriori算法实现购物篮分析

版权声明:本文为原创文章,版权归 Helo 所有。
本文链接:https://www.ishelo.com/archives/233/
商业转载请联系作者获得授权,非商业转载请注明出处。

2 comments
加油!快点好起来
早点康复